前言
学习粒子滤波,主要是为了大创的IVR,系统的学习了一遍之后,发现大创也就如此,之前的一些疑惑都统统扫除,感觉自己也能对别人的论文挥斥方遒一样(bushi)
视频链接
# 贝叶斯公式
离散:
P(X=x∣Y=y)=P(Y=y)P(Y=y∣X=x)P(X=x)
连续:
P(X<x∣Y=y)=P(Y=y)P(Y=y∣X<x)P(X<x)
定理:
fX(x)∼N(u1,σ12),fY∣X(y∣x)∼N(u2,σ22)fX∣Y(x∣y)∼N(σ12+σ22σ12u2+σ12+σ22σ22u1,σ12+σ22σ12σ22)
分析:
若σ12≫σ22,fX∣Y(x∣y)∼N(σ12+σ22σ12u2+σ12+σ22σ22u1,σ12+σ22σ12σ22)≈N(u2,σ22)(倾向观测值)若σ12≪σ22,fX∣Y(x∣y)∼N(σ12+σ22σ12u2+σ12+σ22σ22u1,σ12+σ22σ12σ22)≈N(u1,σ21)(倾向预测值)
狄拉克函数
δ(x)={0,∞,x=0x=0满足∫−∞+∞δ(x)dx=1
实质上δ(x)为必然事件的概率密度
H(x)={1,0,x≥0x<0则δ(x)=dxdH(x)
定理:
∫−∞+∞f(x)δ(x)dx=f(0)
推论:
∫abδ(x)dx=1∫abf(x)δ(x)dx=f(0)∫cdf(x)δ(x−a)dx=f(a)a<0<ba<0<bc<a<d
贝叶斯滤波算法
状态方程:观测方程:Xk=f(Xk−1)+QkYk=H(Xk)+Rk
算法:
初值:预测步:更新步:期望估计值:X0∼f0(x)fk−(x)=∫−∞+∞fQk(x−f(v))fk−1+(v)dvfk+(x)=ηkfRk(yk−h(x))fk−(x),ηk=[∫−∞+∞fRk(yk−h(x))fk−(x)]−1x^k+=∫−∞+∞xfk+(x)dx
缺点:难以处理无穷积分
对策:
f(xk−1),h(xk)为线性函数Qk,Rk为正态分布f(xk−1),h(xk)为非线性函数Qk,Rk为正态分布⇒Kalman Filter卡尔曼滤波⇒Extend Kalman Filter拓展卡尔曼滤波
|
速度 |
精度 |
稳定性 |
| EKF |
快 |
差 |
较稳定 |
| PK |
慢 |
高 |
较稳定 |
| UKF |
较快 |
较高 |
很不稳定,易崩溃(维度越高越不稳定) |
卡尔曼滤波
条件:
f(xk−1)=FXk−1h(xk)=hXk假设为线性函数
fQ(x)=2πQ1e−2Rx2fR(x)=2πR1e−2Rx2
设Xk−1∼N(uk−1+,σk−1+)Q∼N(0,Q)R∼N(0,R)
算法:
uk−=Fuk−1+σk−=F2σk−1++QK=h2σk−+Rhσk−uk+=uk−=K(yk−huk−)σk+=(1−Kh)σk−
分析:K=h2−R/σk−h
若R≫σk−,K→0,uk+=uk−+K(yk−huk−)→uk−若R≪σk−,K→h1,uk+=uk−+K(yk−huk−)→hyk(倾向预测值)(倾向预测值)
矩阵形式的卡尔曼滤波
uk⇒ukσk⇒∑kF、H、Q、R皆为矩阵
算法:
uk−∑k−Kuk+∑k+=Fuk−1−=F∑k−1−FT+Q=∑k−HT(H∑k−HT+R)−1=uk−+K(yk−Huk−)=(I−KH)∑k−
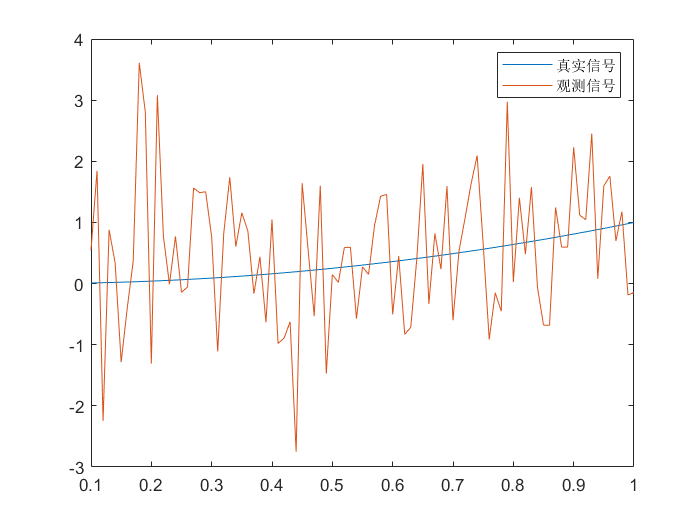
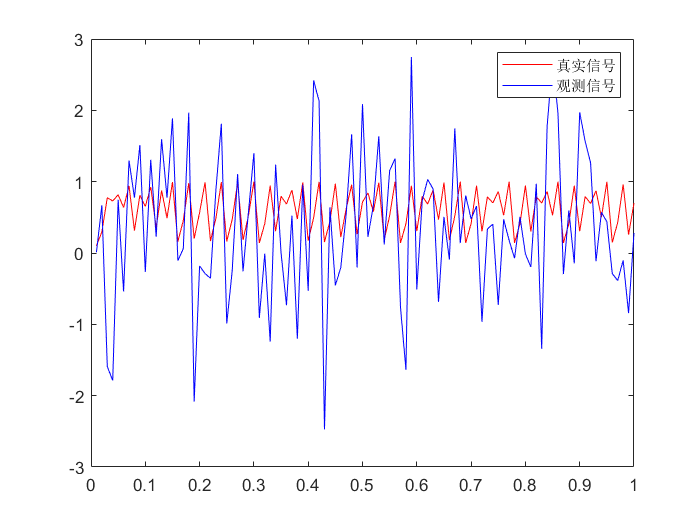
生成高斯噪声信号:
x=t2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
t = 0.1:0.01:1;
L = length(t);
x = zeros(1, L);
y = x;
for i = 1:L
x(i) = t(i)^2;
y(i) = x(i) + normrnd(0, 1);
end
plot(t, x, t, y);
legend('真实信号','观测信号');
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| function Xplus = Kalman_Filter(y, F, Q, H, R, Xplus_0, Pplus_0)
L = length(y);
n = length(F);
Xplus = zeros(n, L);
Xplus(:, 1) = Xplus_0;
Pplus = Pplus_0;
for i = 2:L
Xminus = F * Xplus(:, i - 1);
Pminus = F * Pplus * F' + Q;
K = (Pminus * H') * inv(H * Pminus * H' + R);
Xplus(:, i) = Xminus + K * (y(i) - H * Xminus);
Pplus = (eye(n) - K * H) * Pminus;
end
end
|
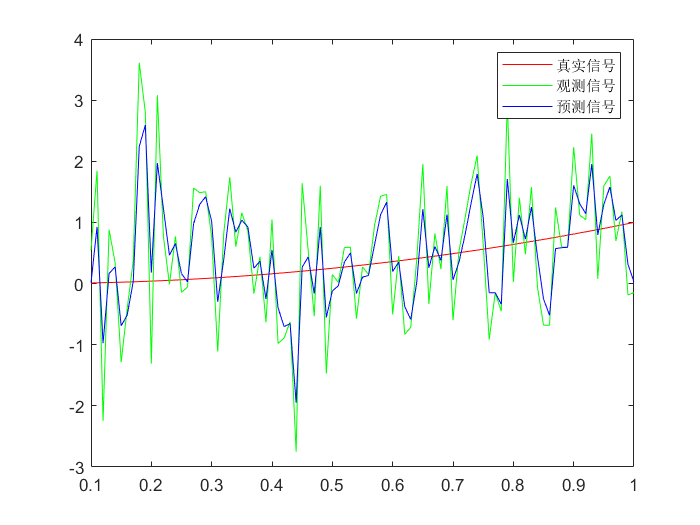
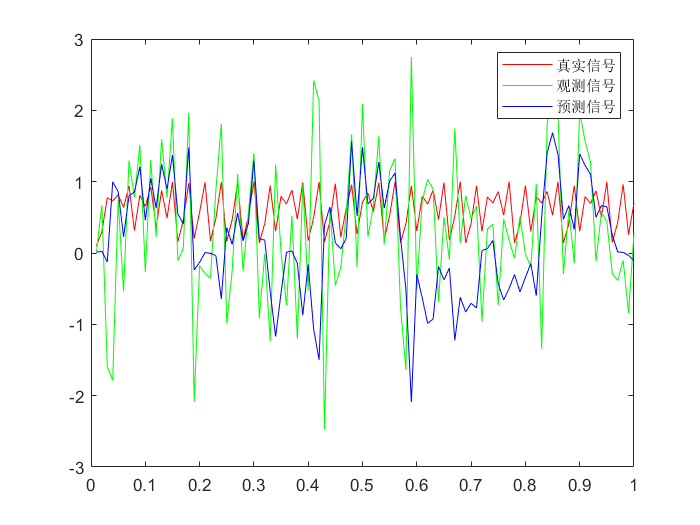
简单模型:
Xk=Xk−1+QYk=Xk−1+R
1
2
3
4
5
6
7
8
9
10
11
12
| >> F = 1;
>> H = 1;
>> Q = 1;
>> R = 1;
>> Xplus_0 = 0.01;
>> Pplus_0 = 0.01^2;
>> Xplus1 = Kalman_Filter(y, F, H, Q, R, Xplus_0, Pplus_0);
>> plot(t, x, 'r', t, y, 'g', t, Xplus1, 'b');
>> legend('真实信号', '观测信号', '预测信号');
|
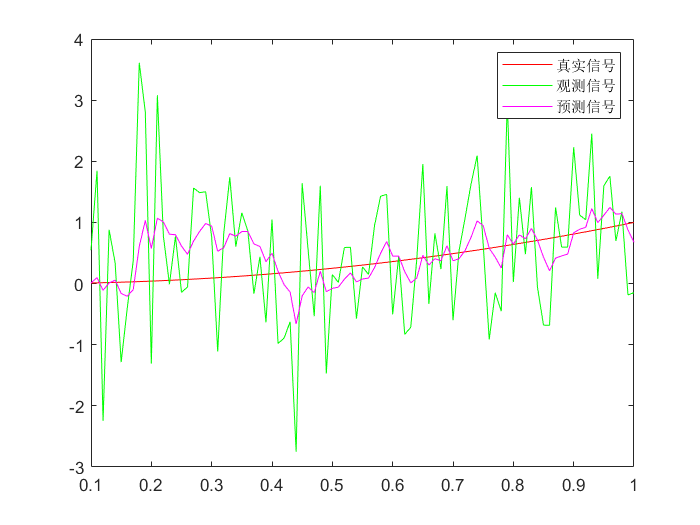
预测方程优化:
XkXk′Xk′′=Xk−1+Xk−1′dt+Xk−1′′2!(dt)2=Xk−1′+Xk−1′dt=Xk−1′′dt
1
2
3
4
5
6
7
8
9
10
11
12
13
| >> dt = t(2) - t(1);
>> F = [1, dt, 0.5 * dt^2; 0, 1, dt; 0, 0, 1];
>> H = [1, 0, 0];
>> Q = [1, 0, 0; 0, 0.01, 0; 0, 0, 0.0001];
>> R = 20;
>> Xplus_0 = [0.1^2, 0, 0];
>> Pplus_0 = [0.01, 0, 0; 0, 0.01, 0; 0, 0, 0.0001];
>> Xplus2 = Kalman_Filter(y, F, Q, H, R, Xplus_0, Pplus_0);
>> plot(t, x, 'r', t, y, 'g', t, Xplus2(1, :), 'm');
>> legend('真实信号', '观测信号', '预测信号');
|
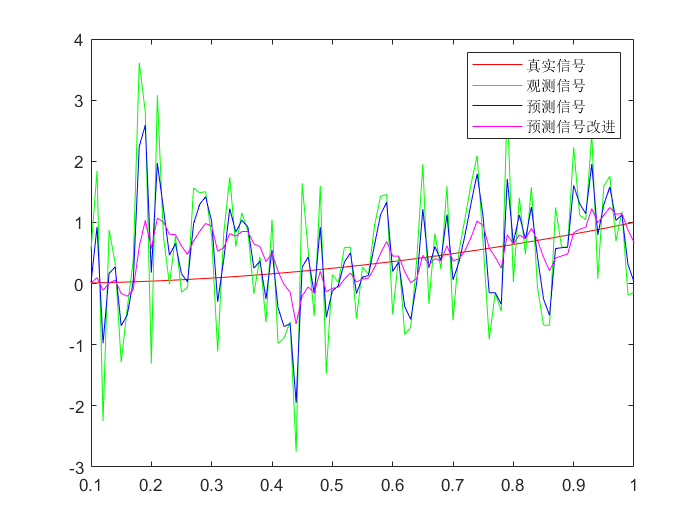
综合比较:
1
2
3
| >> plot(t, x, 'r', t, y, 'g', t, Xplus1, 'b', t, Xplus2(1, :), 'm');
>> legend('真实信号', '观测信号', '预测信号', '预测信号改进');
|
拓展卡尔曼滤波
条件:
f(xk−1) 与 h(xk)假设为非线性函数
对f(xk−1)与h(xk)线性化
状态方程: 泰勒展开: 令预测方程: 观测方程: 泰勒展开: 令更新方程: Xk=f(Xk−1)+QkXk−1∼N(x^k−1+,Pk−1+)f(xk−1)≈f(x^k−1+)+f′(x^k−1+)(Xk−1−x^k−1+)≈f′(x^k−1+)Xk−1+[f(x^k−1+)−f′(x^k−1+)x^k−1+]A=f′(x^k−1+)B=f(x^k−1+)−f′(x^k−1+)x^k−1+Xk=AXk−1+B+QkYk=f(Xk)+RkXk∼N(x^k−,Pk−)h(xk)≈h(x^k−)+h′(x^k−)(Xk−x^k−)≈h′(x^k−)Xk+[h(x^k−)−h′(x^k−)x^k−]C=h′(x^k−)D=h(x^k−)−h′(x^k−)x^k−Yk=CXk+D+Rk
算法:
预测步: 更新步: Xk−1∼N(x^k−1+,pk−1+)A=f′(x^k−1+)x^k−=f(x^k−1+)Pk−=A2Pk−1++QC=h′(x^k−)K=C2Pk−+RCPk−x^k+=x^k−+K(yk−h(x^k−))Pk+=(1−KC)Pk−
矩阵形式:
Axk−∑k−1−CKxk+∑k+Xk−1∼N(x^k−1+,∑k−1+)=⎝⎛∂xk−1(1)∂f1⋮∂xk−1(1)∂fn∂xk−1(2)∂f1⋮∂xk−1(2)∂fn⋯⋱⋯∂xk−1(n)∂f1⋮∂xk−1(n)∂fn⎠⎞=f(x^k−1+)=A∑k−1+AT+Q=⎝⎛∂xk(1)∂h1⋮∂xk(1)∂hn∂xk(2)∂h1⋮∂xk(2)∂hn⋯⋱⋯∂xk(n)∂h1⋮∂xk(n)∂hn⎠⎞=∑k−CT(C∑k−CT+R)=xk−+K(y−h(xk−))=(I−KC)∑k−
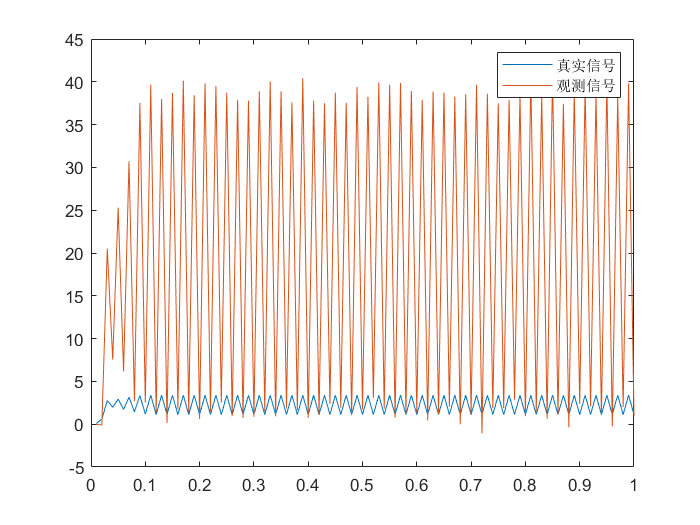
生成高斯噪声信号:
真实数据:xi观测数据:yi=sin(3xi−1)=xi2+R
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
t = 0.01:0.01:1;
n = length(t);
x = zeros(1, n);
y = zeros(1, n);
x(1) = 0.1;
y(1) = 0.1^2;
for i = 2:n
x(i) = sin(3 * x(i - 1));
y(i) = x(i)^2 + normrnd(0, 1);
end
plot(t, x, 'r', t, y, 'b');
legend('真实信号', '观测信号');
|
注:只对一维的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| function Xplus = Extend_Kalman(y, F, Q, H, R, Xplus_0, Pplus_0)
n = length(y);
Xplus = zeros(1, n);
f=sym(F);
df=diff(f);
dF=matlabFunction(df);
h=sym(H);
dh=diff(h);
dH=matlabFunction(dh);
Pplus = Pplus_0;
Xplus(1) = Xplus_0;
for i = 2:n
A = dF(Xplus(i - 1));
Xminus = F(Xplus(i - 1));
Pminus = A * Pplus * A' +Q;
C = dH(Xminus);
K = Pminus * C * inv(C * Pminus * C' +R);
Xplus(i) = Xminus + K * (y(i) - H(Xminus));
Pplus = (eye(1) - K * C) * Pminus;
end
end
|
1
2
3
4
5
6
7
8
9
10
11
12
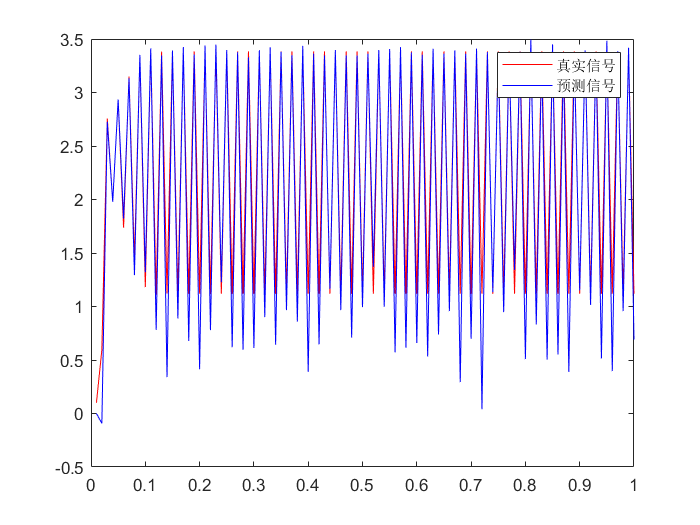
| >> F = @(x)sin(x);
>> H = @(x)x^2;
>> Q = 1;
>> R = 1;
>> Xplus_0 = 0.01;
>> Pplus_0 = 0.01^2;
>> Xplus = Extend_Kalman(y, F, Q, H, R, Xplus_0, Pplus_0)
>> plot(t, x, 'r', t, y, 'g', t, Xplus, 'b');
>> legend('真实信号', '观测信号', '预测信号');
|
原因:多峰问题。观测方程yi=xi2+R有两个解
粒子滤波器
条件:
XkYkX0,Q1,…,=f(xk−1)+Qk=h(xk)+RkQk,R1,…,Rk相互独立
算法:
(1)(2)(3)(4)(5)(6)(7)(8)初值 X0∼N(u,σ2)生成n个X0样本 x0(1),…,x0(n)生成X0样本对应权重 ω0(i)(ω0(i)=n1 or ∑i=1nf(x0(i))f(x0(i)))⋯⋯预测步开始生成Xk−的样本 xk−(i)=f(x0(i))+Q预测步的分布函数 fk−(x)=i=1∑nωk−1(i)δ(x−xk(i))预测步结束观测到数据yk更新步的分布函数 fk+(x)=ηfR(yk−h(x))fk−(x)=i=1∑nη fR(yk−h(x)) ωk−1(i)δ(x−xk(i))改变粒子权重 ωk(i)=fR(yk−h(x−(i)))ωk−1(i)fR=2πσ1e−2σ2x2归一化 η=(i=1∑nωk(i))−1估计期望位置 x^k+=E(x)=∫−∞+∞i=1∑nωk(i)δ(x−xi)dx=i=1∑nωk(i)xi方差 D(X)=E(X2)−[E(X)]2=∫−∞+∞x2f(x)dx−(∫−∞+∞x2f(x)dx)2=i=1∑n[ωk(i)xi2−(x^k+)2]更新步结束……
生成高斯噪声信号:
真实数据:xi观测数据:yi=sin(xi−1)+xi−12+15xi−1=xi3+R
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
t = 0.01:0.01:1;
x = zeros(1, 100);
y = zeros(1, 100);
x(1) = 0.1;
y(1) = 0.01^3;
for i = 2:100
x(i) = sin(x(i - 1)) + 5 * x(i - 1) / (x(i - 1)^2 + 1);
y(i) = x(i)^3 + normrnd(0, 1);
end
plot(t, x, t, y);
legend('真实信号','观测信号');
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
| function Xplus = Particle_Filter(y, F, Q, H, R, n, Nth, Xplus_0)
L = length(y);
Xold = zeros(1, n);
Xnew = zeros(1, n);
Xplus = zeros(1, L);
w = zeros(1, n);
for i = 1:n
Xold(i) = Xplus_0;
w(i) = 1 / n;
end
for i = 2:L
for j = 1:n
Xold(j) = F(Xold(j)) + normrnd(0, Q);
end
for j = 1:n
w(j) = exp(- (y(i) - H(Xold(j)))^2 / (2 * R));
end
w = w / sum(w);
Neff = 1 / sum(w .* w);
if Neff < Nth * n
c = zeros(1, n);
c(1) = w(1);
for j = 2:n
c(j) = c(j - 1) + w(j);
end
for j = 1:n
a = unifrnd(0, 1);
for k = 1:n
if a < c(k)
Xnew(j) = Xold(k);
break;
end
end
end
Xold = Xnew;
for j = 1:n
w(j) = 1 / n;
end
end
for j = 1:n
Xplus(i) = Xplus(i) + Xold(j) * w(j);
end
end
end
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| >> F = @(x)sin(x) + 5 * x / (x^2 + 1)
>> H = @(x)x^3
>> Q = 1;
>> R = 1;
>> n = 100;
>> Nth = 0.5;
>> Xplus_0 = 0.01;
>> Xplus = Particle_Filter(y, F, Q, H, R, n, Nth, Xplus_0);
>> plot(t, x, 'r', t, y, 'g', t, Xplus, 'b');
>> legend('真实信号', '观测信号', '预测信号');
|
1
2
3
| >> plot(t, x, 'r', t, Xplus, 'b');
>> legend('真实信号', '预测信号');
|
感想
毕业了,其实到了最后因为一些特殊的原因(现在回想起来两个人其实也不该)我的大创就终止了,但是没想到会在最后结题答辩的时候翻车,说心里话有一些对不起我的大创老师。虽然大创可能在教授的研究生涯中根本算不上一个科研项目,但是对于我们本科生而言真的是提前开眼。感谢我们的大创老师的栽培以及研究生学长学姐的相助,若没有本科的大创的科研训练,恐怕我研究生的项目也无法如此快速的入手。